Machine learning models and transformers have the ability to convert inputs, such as words, phrases, images and really anything into vector embeddings. These embeddings are used to represent the input in a numerical form that enable computers to perform similarity calculations. See an example below:
{
"vector": [
-0.0033736410550773144,
0.07936657965183258,
-0.06529629230499268,
-0.007808310445398092,
...
]
}Embeddings
One popular method for training word embeddings is the Word2Vec algorithm. This learns to generate embeddings by predicting the context words given a center word.
A quick example of how to train word embeddings using the Word2Vec algorithm:
from gensim.models import Word2Vec
# Define a sentence corpus
sentences = [["cat", "sat", "on", "the", "mat"], ["the", "cat", "fell", "asleep"]]
# Train the Word2Vec model
model = Word2Vec(sentences, size=100, window=5, min_count=1)
# Access the word embeddings
word_vectors = model.wv
# Print the embedding of the word 'cat'
print(word_vectors["cat"])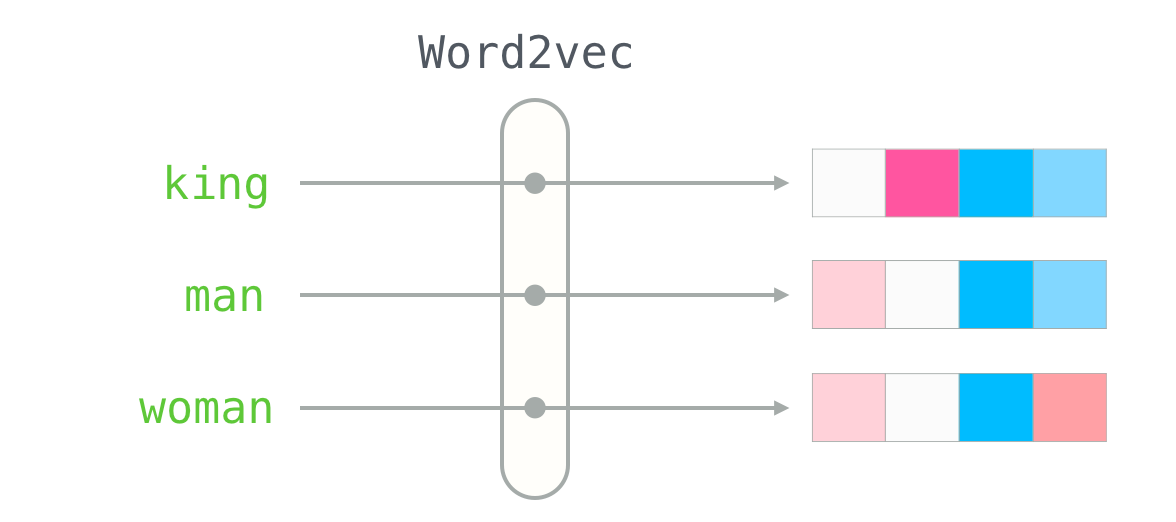
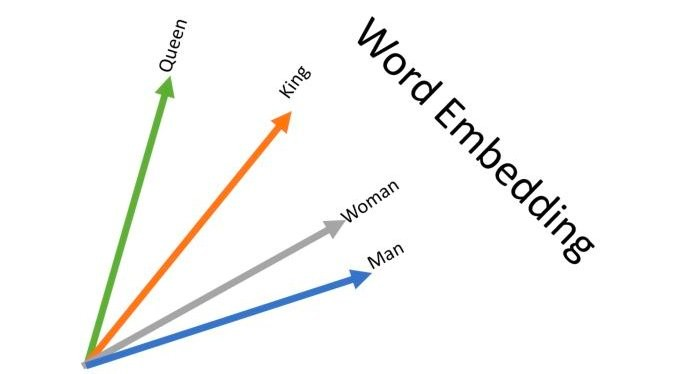
Once we have these words stored in their vector representation, we can perform basic geometry like euclidian distance and cosine functions to determine the "distance" between words. Distance is anbalagous to similarity:
Transformers
Another way to convert inputs into vector embeddings is through the use of transformer models such as BERT and GPT-3.
The major breakthrough in this space was through the publication of a research paper called: Attention is all You Need
In a transformer model, the self-attention mechanism is implemented through the use of attention layers. These layers take in the input, which is typically a sequence of words, and generate a set of attention weights. These attention weights represent the importance of each word in the input in relation to the others.
General pseudocode for how it works:
# Define the input as a sequence of words
input_sequence = [word1, word2, ..., wordN]
# Convert the input words into word embeddings
word_embeddings = EmbeddingLookup(input_sequence)
# Apply the self-attention mechanism to the word embeddings
attention_weights = SelfAttention(word_embeddings)
contextualized_embeddings = WeightedSum(word_embeddings, attention_weights)
# Pass the contextualized embeddings through multiple transformer layers
transformer_output = TransformerLayers(contextualized_embeddings)
# Use the transformer output for downstream NLP tasks such as language understanding,
# machine translation, question answering, etc.
task_output = TaskSpecificHead(transformer_output)
EmbeddingLookup(input_sequence): This step converts the input words into word embeddings, which are numerical representations of the words that capture their meaning in context.SelfAttention(word_embeddings): This step applies the self-attention mechanism to the word embeddings. The self-attention mechanism calculates attention weights for each word in the input, which represent the importance of each word in relation to the others.WeightedSum(word_embeddings, attention_weights): This step calculates a weighted sum of the word embeddings, where the weights are the attention weights calculated in the previous step. This generates contextualized embeddings that capture the meaning of each word in the input in relation to the others.TransformerLayers(contextualized_embeddings): This step applies multiple layers of the transformer model to the contextualized embeddings. These layers include feed-forward neural networks and additional self-attention mechanisms that refine the representation of the input.TaskSpecificHead(transformer_output): This step applies a task-specific head to the transformer output, which is used to generate the final output of the transformer model for a specific NLP task such as language understanding, machine translation, question answering, etc.
Transformers in Action
# import dependencies
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# prepare corpus
corpus = "Japan is an island country in East Asia. It spans an archipelago of 6852 islands."
docs = corpus.split('.')
corpus_vector = model.encode(docs)
# prepare question
query = "How many islands are comprised of Japan?"
query_vector = model.encode(query)
# calculate similarity
scores = util.cos_sim(query_vector, corpus_vector)[0].cpu().tolist()"It spans an archipelago of 6852 islands." esteininger
esteininger
Seems magical right? We can train computers to understand how contextually similar different words are. Now, we can apply that same formula to pictures, videos, audio, images, etc.
This allows us to "discover" content that has similar characteristics, which is how most personalization engines like TikTok, Intagram, and Pinterest work.
Abstracted Down to 2 Lines of Code
Mixpeek boils down all this complexity into two lines of code:
from mixpeek import Mixpeek
mix = Mixpeek("YOUR_API_KEY")
# extract the embedding of an image and store it
mix.index("astronaut_rides_horse.png")
# do the same for text
mix.index("an astronaut riding a horse on mars")Now we can do a search that spans both of these indexed pieces of content (and their vector embedding):
mix.search("space horse")
[
{
"file_id": "63a86c1bf1fc46279ef7614d",
"filename": "astronaut_rides_horse.png",
"importance": "95%"
},
{
"file_id": "63a86c21f1fc46279ef7614e",
"text": "an astronaut riding a horse on mars",
"importance": "72%"
}
]