


The standard design pattern when you want to serve non JSON data to your client is to first store it in S3, then send that object's public file_url to your transactional database of choice.
While MongoDB does have GridFS support, it's not always effective due to filesize limitations. This is why it's encouraged to take advantage of cheap cold storage, and then simply use that s3_url as a reference in your mongoDB collection like:
{
"s3_url": "https://s3.resume.pdf",
"filename": "Ethan's Resume",
"metadata": {}
}This allows our client to decide how they want to process the object. However some issues comes up:
- What if we want to access the contents?
- What if we want our server to process it before sending to the client?
- What if we want to do fancy AI on top of the documents, images, video or audio
This is where multimodal indexing comes in.
How does it work?
Once you create a Mixpeek connection to your S3 bucket as the source, every new object added to that bucket will be streamed into your Mixpeek ML pipeline then the output sent right into your MongoDB collection.
Mixpeek supports three steps out of the box, but still grants the capability of BYO docker containers for custom AI-powered chaining.
- Extract: If it's a PDF, the table contents, text and even images are pulled out. Audio gets transcribed, video can be object/motion tagging and image can be OCR or object detection. Read the extract docs
file_output = mixpeek.extract.text(file_url="s3://document.pdf")- Generate: If it's text, you can instruct the pipeline to use ML to generate a summary or tags. Read the generate docs
class Authors(BaseModel):
author_email: str
class PaperDetails(BaseModel):
paper_title: str
author: Authors
response = mixpeek.generate(
model="gpt-3.5-turbo",
modality="text",
response_format=PaperDetails,
context=f"Format this document: {file_output}",
)- Embed: Supply your own transformer embeddings or use ours (everything is open source). We'll embed the extracted contents or the raw files using text encoders, video encoders, image encoders or audio. Read the embed docs
embedding = mixpeek.embed(
modality="text",
input="hello world",
model="jinaai/jina-embeddings-v2-base-en"
)All of these methods are abstracted into a single pipeline: https://docs.mixpeek.com/pipelines/create
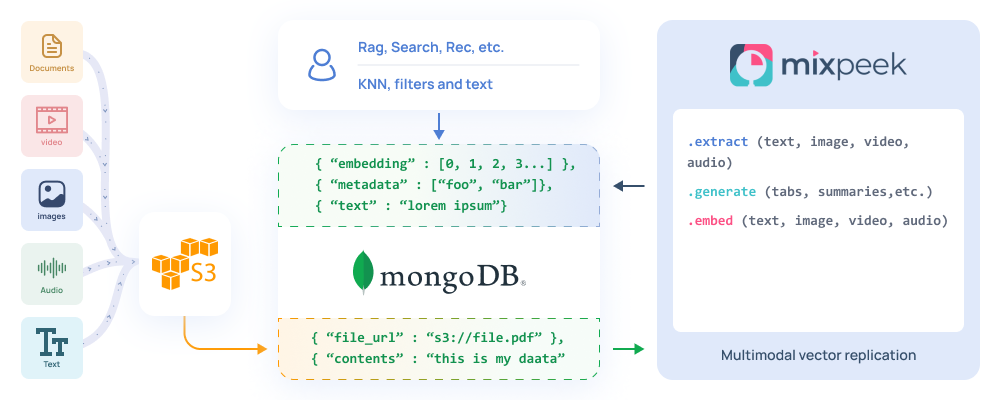
Now to combine it all into a single change data capture, AI-powered ETL from S3 into your MongoDB collection:
from mixpeek import Mixpeek, FileTools, SourceS3
def handler(event, context):
mixpeek = Mixpeek("API_KEY")
file_url = SourceS3.file_url(event['bucket'], event['key'])
pdf_data = FileTools.load_document(file_url)
num_pages = FileTools.document_page_count(pdf_data)
results = []
for page_number in range(1, num_pages + 1):
page_text = FileTools.extract_text(pdf_data, page_number)
page_embedding = mixpeek.embed.text(
input=page_text,
model="sentence-transformers/all-MiniLM-L6-v2"
)
obj = {
"page_number": page_number,
"text": page_text,
"embedding": page_embedding,
"file_url": file_url
}
results.append(obj)
return resultsThis creates an event stream from your S3 bucket so that every change from your bucket invokes your pipeline endpoint and stores the output in your collection.
One major point of frustration developers experience is "what happens if I modify my representative data". Objects in your MongoDB collection are rarely static, they change often. As does your S3 bucket.
Mixpeek understands inserts vs updates vs deletes and is able to intelligently handle the embeddings by replacing/updating them in real-time.
Cool so now what can we do? Hybrid search.
Once we have vectors, tags, and embeddings the sky is really the limit. We advise writing queries that span these data structures, and MongoDB has you covered.
Here's a MongoDB query that combines:
- text: inverted index using the best full text search engine, Lucene
- $knnBeta: stored vectors with K nearest neighbors similarity
- compound.filter: standard MongoDB B-tree indexes
[
{
$vectorSearch: { // KNN query
index: "indexName",
path: "fieldToSearch",
queryVector: [0, 1, 2, 3],
filter: {
$and: [
{
freshness: {
$eq: "fresh",
},
year: {
$lt: 1975,
},
},
], // text and integer (pre-filtering)
},
},
},
{
$match: {
foo: "bar",
},
}, // standard mongodb query
]More advanced query that enables hybrid search in MongoDB: https://www.mongodb.com/docs/atlas/atlas-vector-search/tutorials/reciprocal-rank-fusion/
What about Multimodal Retrieval Augment Generation?
Send the query results to an LLM for "reasoning". Mixpeek has a library that lets you structure the output:
class Authors(BaseModel):
author_email: str
class PaperDetails(BaseModel):
paper_title: str
author: Authors
response = mixpeek.generate(
model={"provider":"GPT", "model":"gpt-3.5-turbo"},
response_format=PaperDetails,
context=f"format this document and make sure to respond and adhere to the provided JSON format: {corpus}",
messages=[],
settings={"temperature":0.5},
)Here we're supplying a corpus to our GPT model and telling it to structure the output in a certain way based on Pydantic schemas.
This returns amazing, structured outputs:
{
"author": {"author_email": "shannons@allenai.org"},
"paper_title": "LayoutParser: A Unifiend Toolkit for Deep Learning Based"
}Completely free AI playground to use these methods: https://mixpeek.com/start
Benefits of Mixpeek & MongoDB
- Consistent: Leveraging MongoDB's change streams, every write is causally consistent
- Multimodal: One query that spans multiple indexes and embedding spaces
- Durable: Mixpeek ensures the entire process per write has guaranteed execution
- Atomic: If one step fails in the pipeline, nothing get's written so you don't have any half-written data
What else can you build?
- Video Understanding Platforms: https://learn.mixpeek.com/semantic-video-understanding
- eCommerce Search: https://learn.mixpeek.com/visual-shopping/
- Financial Analysis: https://github.com/mixpeek/use-cases/tree/master/2023-market-outlooks
Much, much more. The sky is the limit with multimodal AI....
