


Amazon S3 is the defacto storage for unstructured data. Pictures, video, audio, documents, the list goes on. How do engineers integrate S3 objects in their application? Typically this is done via metadata like tags, titles and descriptions. The creation of this metadata is manually intensive, and then it has to be maintained as your files and application design patterns evolve.
Metadata is not enough in the age of AI. To deliver exceptional experiences that make use of your S3 bucket, you need a multimodal index.
To build a multimodal index that understands your S3 bucket, you typically need to build the following:
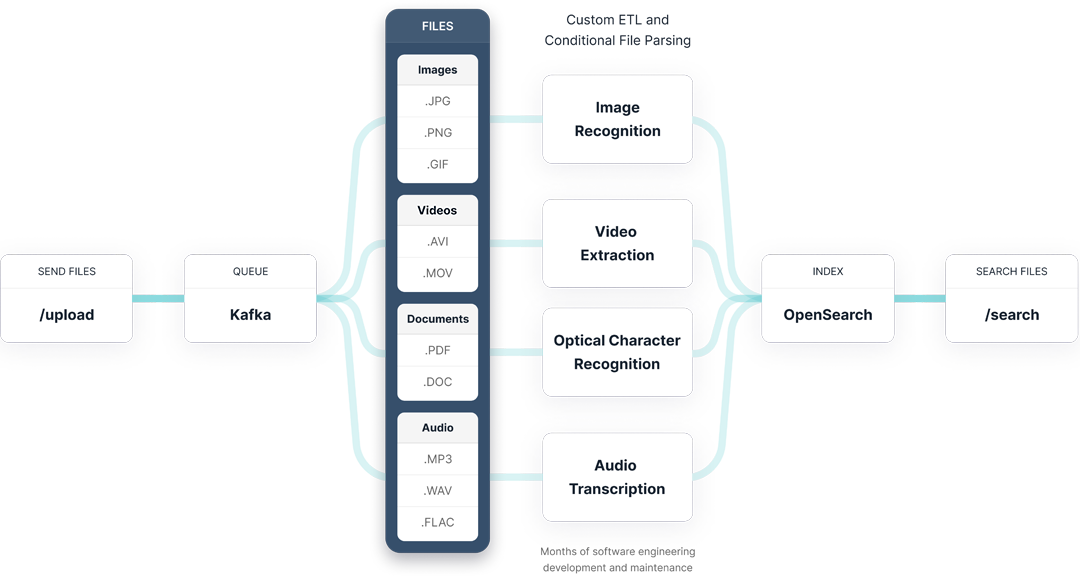
This is a change data capture stream like Kafka, various parsers depending on file-type, and index.
Mixpeek allows developers to bring their own storage, database and even docker containers to streams changes from your source (S3 in this case) through your pipeline of ML services, and sends the output to your MongoDB collection(s).
Provision an IAM role, then whenever a new file (object) is added to your bucket, Mixpeek will automatically extract its contents, generate embeddings, metadata, and text, and then load it into your MongoDB collection.
With Mixpeek we can collapse the above diagram into this:

The ETL Process
Extract: Mixpeek monitors your configured S3 bucket for new file uploads. When a new file is detected, Mixpeek automatically retrieves and processes the file, regardless of its format (text, image, audio, or video).
Transform: In the transformation phase, Mixpeek performs several operations on the extracted data:
- Content Extraction: Mixpeek extracts the content from the file, whether it's text, images, audio, or video.
- Embedding Generation: Mixpeek generates embeddings, which are vector representations of the content. These embeddings are useful for tasks like similarity search and clustering.
- Metadata Extraction: Mixpeek extracts relevant metadata from the file, such as file type, size, creation date, and any other custom metadata.
- Text Generation: For non-text files (e.g., images, audio, video), Mixpeek generates text descriptions or transcripts using advanced machine learning models.
Load: After transforming the data, Mixpeek loads the extracted content, embeddings, metadata, and generated text into your MongoDB collection. This allows you to store and query the data efficiently within your MongoDB database.
Here's an example of how the data might be structured in your MongoDB collection after Mixpeek processes a PDF file:
{
"_id": ObjectId("63a2d6b7f03e1d8e8f724967"),
"text": "This is the extracted text content from the PDF file.",
"embeddings": [...], // Vector embeddings representing the content
"metadata": {
"fileName": "example.pdf",
"fileType": "application/pdf",
"fileSize": 123456,
"createdAt": ISODate("2023-05-12T10:30:00Z")
}
}Under the hood, here's what we're able to do:

Example Usage
To get started with Mixpeek, you'll need to connect your Amazon S3 bucket and MongoDB collection. Here's an example of how you might set up the pipeline using Mixpeek's API:
import mixpeek as client
# Connect to Mixpeek
mixpeek = client(api_key="your_api_key")
# Configure the S3 source connection
s3_connection_id = mixpeek.connection(
engine="s3",
region_name="us-east-2",
bucket="your-bucket",
iam_role_arn="arn:aws:iam::123456789012:role/your-role",
)
# Configure the MongoDB destination
mongodb_connection_id = mixpeek.connection(
engine="mongodb",
connection_string="mongodb://username:password@host:port/database"
)
# Create and enable the pipeline
pipeline = mixpeek.Pipeline(
name="my-pipeline",
source=s3_connection_id,
destination=mongodb_connection_id
)
pipeline.enable()Two pre-requisites to note:
- S3: The IAM role in this mixpeek.connection() should have the permissions laid out here: https://docs.mixpeek.com/connections/s3
- MongoDB: The database user needs to have permsissions and you need to provision network access to Mixpeek's API servers: https://docs.mixpeek.com/connections/mongodb
With this setup, Mixpeek will continuously monitor your S3 bucket for new file uploads and automatically extract, transform, and load the data into your MongoDB collection leaving you with fresh, in-sync embeddings, metadata and text always.
Combine with Langchain for RAG Q&A
After the Mixpeek ETL process, your MongoDB collection should contain documents with fields like content, embeddings, metadata, and text. We can use LangChain to set up a RAG pipeline for question answering.
import os
from pymongo import MongoClient
from sentence_transformers import SentenceTransformer
from langchain.embeddings import SentenceTransformersEmbeddings
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# Set environment variables for sensitive information
ATLAS_CONNECTION_STRING = "your_atlas_connection_string"
OPENAI_API_KEY = "your_openai_api_key"
# Connect to MongoDB Atlas cluster
cluster = MongoClient(ATLAS_CONNECTION_STRING)
# Define MongoDB database and collection names
DB_NAME = "langchain"
COLLECTION_NAME = "vectorSearch"
MONGODB_COLLECTION = cluster[DB_NAME][COLLECTION_NAME]
# Load the pre-trained sentence transformer model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Initialize the LangChain SentenceTransformersEmbeddings
embeddings = SentenceTransformersEmbeddings(model=model)
# Initialize MongoDB Atlas vector search
vector_search = MongoDBAtlasVectorSearch(
collection=MONGODB_COLLECTION,
embedding=embeddings,
index_name="default"
)
# Initialize the OpenAI language model
openai_llm = OpenAI(api_key=OPENAI_API_KEY)
# Create a retriever from the vector search
retriever = vector_search.as_retriever()
# Create a RetrievalQA chain using the retriever and OpenAI language model
qa_chain = RetrievalQA(llm=openai_llm, retriever=retriever)
# Query text
query_text = "what is the meaning of life?"
# Perform the generative query
result = qa_chain({"query": query_text})
# Print the result
print(result)
Breakdown of the Code
- Connect to MongoDB Atlas Cluster:
A connection to the MongoDB Atlas cluster is established using the provided connection string. - Define Database and Collection Names:
The MongoDB database (langchain) and collection (vectorSearch) are specified to interact with the specific collection within the MongoDB Atlas cluster. - Initialize LangChain Sentence Transformers Embeddings:
TheSentenceTransformersEmbeddingsclass from LangChain is initialized with the pre-trained model, making the model's embeddings compatible with LangChain. - Initialize MongoDB Atlas Vector Search:
AMongoDBAtlasVectorSearchobject is created using the specified MongoDB collection and LangChain-compatible embeddings. This sets up the vector search capability in MongoDB Atlas. - Create a Retriever from Vector Search:
Theas_retrievermethod of the vector search object is used to create a retriever that can fetch relevant documents from the MongoDB collection based on vector embeddings. - Create a RetrievalQA Chain:
ARetrievalQAchain is created using the OpenAI language model and the retriever. The chain type is set to "stuff," which combines the retrieved documents with the question to provide a final answer. - Perform the Generative Query:
Theqa_chainis used to perform the query, combining the question with relevant documents retrieved from the MongoDB collection.
Mixpeek <> MongoDB Empowers
Knowledge Base Creation and Question Answering
Organizations can leverage Mixpeek to automatically ingest unstructured data from S3, extract content, generate embeddings, and store the data in a MongoDB collection. By integrating LangChain's RAG pipeline with this MongoDB collection, they can create a powerful knowledge base capable of answering questions based on the ingested data, making it valuable for customer support teams, research organizations, or scenarios requiring quick access to information buried within large volumes of unstructured data.
Content Analysis and Insights
Mixpeek's ability to process various unstructured data types, including text, images, audio, and video, combined with LangChain's RAG pipeline, enables media companies or businesses to ingest and analyze user-generated content from S3, such as social media posts, product reviews, or customer feedback. By storing the extracted data and embeddings in MongoDB, they can leverage the RAG pipeline to analyze content, identify sentiment, extract key topics or entities, and generate insights or summaries, helping them understand customer preferences, monitor brand reputation, or identify trending topics.
Content Search and Discovery
For organizations with extensive content repositories, the combination of Mixpeek and LangChain can provide a powerful content search and discovery solution. Mixpeek continuously ingests and processes new content from S3, generating embeddings and storing the data in MongoDB. LangChain's RAG pipeline can then build a search engine or content discovery platform that allows users to query the ingested data using natural language queries, enabling semantic search and retrieval of relevant content based on conceptual similarities.
Getting started with Mixpeek and MongoDB Atlas
- MongoDB Atlas Database that indexes movies using embeddings. (Vector Store)
- S3 Bucket for storing files and listening to changes
- Mixpeek API key for real-time, AI-powered ETL
